-
빅데이터분석기사 실기 연습예제 - 2. 예측 모델 생성자격증/빅데이터분석기사 2021. 8. 24. 16:15반응형
빅데이터분석기사 실기 시험을 보고나서 후배들에게 도움을 주고자 만들게 된 예시입니다.
첫 시험(2회차, 1회는 캔슬)이라 상대적으로 쉬었을 수도 있지만 다음 차수도 이번 난이도와 같다는 가정하에 작성하였습니다.
0. 데이터 준비
데이터는 널리 쓰이는 Titanic 데이터를 사용하며 다운로드 경로는 아래와 같다.
https://www.kaggle.com/c/titanic
Titanic - Machine Learning from Disaster | Kaggle
www.kaggle.com
해당 데이터는 타이타닉호에 탑승한 승객들의 데이터이며 생존여부(Survived)를 정답값으로 가진다.
train, test 데이터셋을 사용하며, 실제 시험 및 대회등과 동일한 환경을 구축하기위해 submit 셋을 만든다.
train, test 데이터셋은 아래와 같이 구성되어 있다.
train에는 정답값인 Survived가 추가로 포함되어 있다.

submit 셋은 최종적으로 정답을 입력하여 제출하게될 파일로 아래 코드를 통해 만든다.
실제 시험에서는 제공되므로 아래의 코드는 연습시에만 사용하고 실제로는 주어진 파일을 사용하자.
submit_df = pd.DataFrame({'PassengerId':[],'0_proba':[],'1_proba':[]}) submit_df['PassengerId'] = test['PassengerId'] submit_df['0_proba'] = [0 for i in test.index] submit_df['1_proba'] = [0 for i in test.index]
1. 라이브러리 선언
본 글에서는 전처리 라이브러리로 pandas, numpy, sklearn, xgboost를 사용한다.
import pandas as pd import numpy as np import sklearn from sklearn.preprocessing import OneHotEncoder,StandardScaler from xgboost import XGBClassifier2. 데이터 분석
기본적은 분석을 수행해본다.
info 명령어를 통해서 총 row 수, 결측값이 존재하는 컬럼, 컬럼별 데이터 타입 등을 알 수 있다.
print(train.info())
nunique 명령어로는 컬럼별로 고유의 값을 파악 할 수 있다.
print(train.nunique())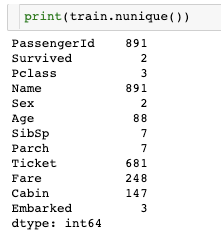
3. 데이터 전처리
3-1. 불필요 컬럼 제거
예측에 불필요하다고 파악되는 값을 삭제한다
Name : 모든 값이 고유함
Ticket : 대부분의 값이 고유함
# 불필요 컬럼 삭제 del_list = ['Name','Ticket'] train = train.drop(del_list,axis=1) test = test.drop(del_list,axis=1)3-2. 범주형 데이터 처리
먼저 범주형 데이터를 처리한다.
(Cabin 컬럼은 범주형 데이터이지만 전처리 기능을 보여주기위해서 수치형 데이터라고 가정한다)
3-2-1. 결측치 채우기
Embarked의 결측치를 "A"라는 고정된 값으로 채운다.
# 결측값 채우기 fill_x = 'A' train['Embarked'] = train['Embarked'].fillna(fill_x) test['Embarked'] = test['Embarked'].fillna(fill_x)3-2-2. 인코딩
범주형 데이터는 그대로 사용할 수 없기 때문에 인코딩을 통해 벡터화 해준다.
가장 보편적인 one-hot 인코딩 방법을 사용한다.
'Pclass'는 정수값을 가지지만 실제로는 범주형 데이터이므로 인코딩을 진행해준다.
"handle_unknown" 속성은 test셋에서 train셋에 없던 데이터가 등장할때 무시하여 에러가 발생 하지 않도록 한다. test셋에 새로운 값이 없다면 없어도 무방하다.
# 인코딩 encoding_list = ['Pclass','Sex','Embarked'] enc = OneHotEncoder(handle_unknown='ignore') enc.fit(train.loc[:,encoding_list]) # 인코더 피팅train셋 인코딩
tmp=pd.DataFrame(enc.transform(train[encoding_list]).toarray(), columns=enc.get_feature_names(encoding_list)) train.drop(encoding_list, axis=1, inplace=True) train = pd.concat([train, tmp], axis=1)
test셋 인코딩
tmp=pd.DataFrame(enc.transform(test[encoding_list]).toarray(), columns=enc.get_feature_names(encoding_list)) test.drop(encoding_list, axis=1, inplace=True) test = pd.concat([test, tmp], axis=1)3-3. 수치형 데이터 전처리
3-3-1. 결측값 채우기
Cabin과 Age 컬럼을 각각의 방법으로 채운다.
nanmedian을 사용하는 이유 : median 함수는 결측값이 존재하는 배열을 입력받으면 에러가 난다.
# 결측값 채우기 # 고정값으로 채우기 fill_x = '0' train['Cabin'] = train['Cabin'].fillna(fill_x) test['Cabin'] = test['Cabin'].fillna(fill_x) # 중앙값으로 채우기 fill_x = np.nanmedian(train['Age']) train['Age'] = train['Age'].fillna(fill_x) test['Age'] = test['Age'].fillna(fill_x)3-3-2. 데이터 정제
Cabin 컬럼을 원래 수치형 값인데 문자열이 섞여 기록되었다고 가정한다.
따라서 Cabin 컬럼값에 포함된 문자들을 지워준다.
re.sub 함수를 통해 문자열을 모두 지워준다. ⇒ re.sub(찾을패턴,대체할문자,입력값)
x가 아닌 '0'+x 를 사용한 이유는 Cabin 컬럼에 문자열로만 이루어진 행이 있어 nan 관련 에러가 발생하기 때문이다.
문자열을 통한 데이터 정제를 보여주려고 Cabin을 숫자형이라 가정하다보니 생긴 문제로 시험에서 주어지는 데이터에서는 이러한 상황이 없을 듯 하다.
# 데이터 정제 # Cabin 컬럼이 원래 숫자지만 문자열이 섞여서 기록되었다고 가정 import re pattern = r'[^\d-]' train['Cabin'] = train['Cabin'].apply(lambda x: int(re.sub(pattern,'','0'+x))) test['Cabin'] = test['Cabin'].apply(lambda x: int(re.sub(pattern,'','0'+x)))3-3-3. 정규화
표준정규화를 사용한다.
fit_transform() 함수는 fit과 transform을 둘다 진행한다.
나누어서 써도 된다. (당연히 위의 범주형 데이터 인코딩에서도 fit_transform으로 한번에 써도 된다)
# 정규화 scaler_list = ['Age','Fare','Cabin','SibSp','Parch'] scaler = StandardScaler() train[scaler_list] = scaler.fit_transform(train[scaler_list]) test[scaler_list] = scaler.transform(test[scaler_list])3-4. 데이터 분할 ( 입력값, 정답값 )
앞서 과정을 통해 train 및 test셋이 전처리되었다.
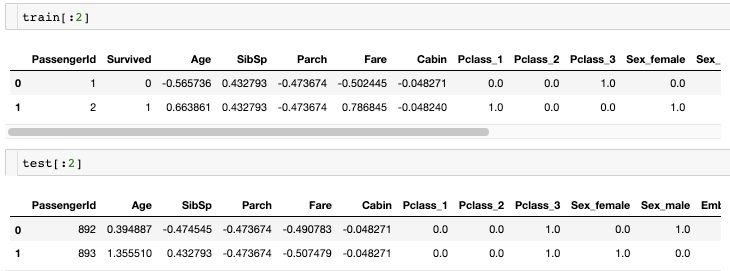
그 다음으로는 train셋에서 정답값인 Survived를 분리해주어야한다.
또한 각 row의 id값인 PassengerId를 제거해준다.
target = train['Survived'][:] train = train.drop(['PassengerId','Survived'],axis=1) test = test.drop(['PassengerId'],axis=1)4. 모델 선언 및 학습
xgboost 모델을 통해 예측을 진행한다.
여러 모델이 있지만 xgboost는 여타 모델들보다 준수한 성능을 보이기에 채택했다.
score 함수는 학습된 모델을 입력된 데이터(입력값,정답값)을 통해 평가해준다.
xgb = XGBClassifier() xgb.fit(train,target) print(xgb.score(train,target))
기본 파라미터만을 사용하여 0.87의 성능을 얻었다. (1.0이 최대)
실제 빅데이터분석기사 실기 시험에서도 파라미터튜닝을 진행하지않고 기본 모델을 사용하여 높은 결과를 얻었다.
5. 예측 및 정답셋 생성
이제 test셋을 통해 예측을 수행한다.
예측의 경우 정답값을 반환 하거나 각 class의 확률을 반환 할 수 있다.
본 포스팅에서 준비한 submit셋은 proba(class별 확률)을 요구하므로 5-a.방법을 통해 진행한다.
5-a. 예측값 반환
predict() 함수는 예측된 정답값을 반환한다.
predicted=xgb.predict(test) print(predicted)
5-b. class별 확률 반환
predict_proba(0과1에 대한 각각의 확률)함수는 각 class에 대한 확률을 반환한다.
predicted=xgb.predict_proba(test) print(predicted)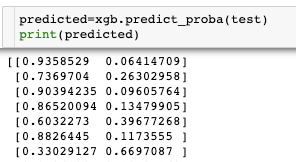
위의 그림과 같이 predicted는 2차원 배열이다.
따라서 아래의 코드를 통해서 각각 class별 확률을 입력해준다.
submit_df['0_proba'] = predicted_df[:,0] submit_df['1_proba'] = predicted_df[:,1]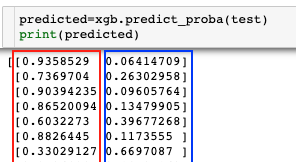
predicted_df[:,0]는 그림의 빨간 박스를 의미하고
predicted_df[:,1]는 파란 박스를 의미한다.
반응형'자격증 > 빅데이터분석기사' 카테고리의 다른 글
[빅데이터분석기사] 실기시험 모의고사 1 (0) 2021.11.29 빅데이터분석기사 실기 연습예제 - 1. 데이터 전처리 (0) 2021.08.23 빅데이터분석기사 2회 실기 합격 후기 및 꿀팁 (0) 2021.08.23