-
빅데이터분석기사 실기 연습예제 - 1. 데이터 전처리자격증/빅데이터분석기사 2021. 8. 23. 13:34반응형
빅데이터분석기사 실기 시험을 보고나서 후배들에게 도움을 주고자 만들게 된 예시입니다.
첫 시험(2회차, 1회는 캔슬)이라 상대적으로 쉬었을 수도 있지만 다음 차수도 이번 난이도와 같다는 가정하에 작성하였습니다.
데이터 준비
데이터는 널리 쓰이는 Titanic 데이터를 사용하며 다운로드 경로는 아래와 같다.
https://www.kaggle.com/c/titanic
Titanic - Machine Learning from Disaster | Kaggle
www.kaggle.com
해당 데이터는 타이타닉호에 탑승한 승객들의 데이터이며 생존여부(Survived)를 정답값으로 가진다.
본 포스팅에서는 데이터 전처리가 목적이므로 train.csv만 활용한다.
라이브러리 선언
import pandas as pd import numpy as np # as는 해당 모듈의 별칭을 지정한다. # 따라서 pandas를 pd라는 별칭으로 지정한다는 의미이다.통계값 구하기
# 최댓값 구하기 max_v = np.max(df['Age']) print('최댓값 : ',max_v) # 최솟값 구하기 min_v = np.min(df['Age']) print('최소값 : ',min_v) # 총합 구하기 sum_v = np.sum(df['Age']) print('총합값 : ',sum_v) # 중앙값 구하기 median_v = np.median(df['Age']) print('중앙값 : ',median_v) # 평균 구하기 mean_v =np.mean(df['Age']) print('평균값 : ',mean_v) # 표준편차 구하기 std_v = np.std(df['Age']) print('표준편차 : ',std_v) # 사분위수 구하기 q1, q3 = np.quantile(df['Age'], [0.25,0.75]) print('사분위수(25%,75%) : ',q1,q3)
실행 결과 위 코드를 실행했을 때의 결과이다.
중앙 값과 사분위수가 nan으로 나타나는 것은 결측값(nan)이 섞여 있기 때문이다.
numpy에서는 결측치를 알아서 배제하고 계산해 주는 함수도 제공된다.
단순하게 앞에 nan을 붙이면 된다.
# 결측치 배제하고 중앙값 구하기 median_v = np.nanmedian(df['Age']) print('중앙값 : ',median_v) # 결측치 배제하고 사분위수 구하기 q1, q3 = np.nanquantile(df['Age'], [0.25,0.75]) print('사분위수(25%,75%) : ',q1,q3)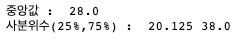
결측값 채우기
Age 컬럼의 결측치를 평균 값으로 채워보자.
x = np.mean(df['Age']) df['Age'] = df['Age'].fillna(x)특정 값을 포함한 row 제거하기
나이가 70세 이상인 데이터를 제거해보자
df = df[df['Age']<70]나이가 20세 미만이거나 60세 이상인 데이터를 제거해보자
df = df[ (20<=df['Age']) & (df['Age']<60) ]컬럼 제거하기
하나의 컬럼 제거하기
df = df.drop(['Age'], axis=1) # 또는 del df['Age']여러개의 컬럼 제거하기
df = df.drop(['Age','Cabin'], axis=1)컬럼 추가하기
추가할 컬럼 이름(new_column)에 리스트를 입력하여서 컬럼을 추가 할 수 있다.
이때 추가되는 리스트의 길이는 기존의 데이터프레임의 길이와 동일해야한다.
lst = [i for i in range(len(df))] df['new_column'] = lst데이터 프레임 합치기
df_total = pd.concat([df_1,df_2],axis=1)문자열 처리
import re pattern = r'[^\d-]' sub_str = re.sub(pattern,'','-1dd1ed1') print(sub_str) 반응형
반응형'자격증 > 빅데이터분석기사' 카테고리의 다른 글
[빅데이터분석기사] 실기시험 모의고사 1 (0) 2021.11.29 빅데이터분석기사 실기 연습예제 - 2. 예측 모델 생성 (0) 2021.08.24 빅데이터분석기사 2회 실기 합격 후기 및 꿀팁 (0) 2021.08.23