-
DBSCAN(Density-based spatial clustering of applications with noise, 밀도기반 군집화) 파이썬구현하기Data Science/ML&DL 모델 2022. 10. 5. 15:56반응형
해당 글에서는 density based clustering(밀도기반 클러스터링,군집화)을 파이썬으로 구현해본다.
사용되는 라이브러리는 아래와 같다.
모델 : sklearn.cluster.DBSCAN
평가 : sklearn.metrics.silhouette_score , silhouette_samples, yellowbrick.cluster.KElbowVisualizer
Clustering에 대한 이론적인 부분은 "클러스터링 기법(개념,타당성,평가)" 글을 참고.
1. 데이터 준비
sklearn에서 제공해주는 iris 데이터를 사용한다.
clustering이기에 종속변수를 제외하고 독립변수만으로 데이터프레임을 구성한다.
import pandas as pd from sklearn import datasets iris = datasets.load_iris() X = iris.data y = iris.target df = pd.DataFrame(X, columns = iris.feature_names) print(df)
clustering에서는 각 독립변수(컬럼)별로 값의 스케일이 다르면 가지게되는 가중치가 달라진다.
( 독립변수 x1이 1000~10000의 값을 가지고 독립변수 x2가 1~3의 스케일을 가질경우 x1의 변화에 따라서 모델이 좌우되고 x2의 변화는 무시된다.)
따라서 스케일링을 통해서 모든 독립변수간의 스케일을 동일하게 맞추어준다.
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() df.loc[:,:] = scaler.fit_transform(df) print(df)
2. DBSCAN 생성 및 학습
sklearn의 모든 모델들과 같이 .fit명령어로 학습한다.
clustering은 비지도 학습이므로 독립변수만을 입력으로 받는다.
기본적인 중심기반 clistering들과는 다르게 cluster 개수를 입력받지 않고 탐지 조건을 입력받는다.(두 샘플간 최대 거리, 핵심포인트 최소 이웃 수)
from sklearn.cluster import DBSCAN dbscan = DBSCAN(eps=0.6, min_samples=2) dbscan.fit(df)파라미터 기능 초기값 파라미터 eps 두 샘플간 최대 거리 0.5 실수값 min_samples 핵심포인트의 최소 이웃 수 5 정수값 metric distance 측정 방법 지정 euclidean ‘cityblock’,‘cosine’,‘euclidean’,‘haversine’,‘l1’,‘l2’,‘manhattan’,‘nan_euclidean’ 분류 결과는 .labels_로 확인가능하다.
이때 -1이라는 라벨이 보이는데, 이는 노이즈(noise)로 판단된 객체에게 배정되는 라벨이다.
노이즈가 많을 경우에는 eps를 낮추거나 min_smaples를 줄여서 해결할 수 있다.
dbscan.labels_
3. 타당성 평가(성능 평가)
Clustering은 정답이 없는 비지도학습이기에 모델의 타당성(또는 성능)을 평가하기위해서 거리값을 사용한다.
중심기반 Clustering 기법과는 다르게 cluster의 개수를 지정하지 않기 때문에 두 샘플간 최대 거리, 핵심포인트 최소 이웃 수를 조정하여 최적의 cluster 조건을 찾는다.
3.1 Silhouette Index(실루엣 인덱스)
clustering 기법에서 실질적으로 가장 많이 쓰이는 타당성(평가) 지표이다.
개별객체마다 silhouette index 값을 구할수 있으며, 이에대한 평균값을 사용한다.
모든값이 0.5 이상을 가지면 유의하다고 판단한다.
a(i) : 객체 i와 객체 i가 속한 cluster 내 다른 객체들간의 거리 평균
b(i) : 객체 i와 다른 군집에 속한 객체들간의 거리평균 중, 가장 최소값을 가지는 군집과의 거리 평균

이때 DBSCAN에서는 Noise 항목이 있기때문에 해당 항목들을 제거하고 silhouette index를 계산한다.
from sklearn.metrics import silhouette_score, silhouette_samples silhouette_avg = silhouette_score(df[dbscan.labels_!=-1], dbscan.labels_[dbscan.labels_!=-1]) print(silhouette_avg) #=>0.5090166526563076해당 포스팅에서는 eps 거리별로 silhouette index를 계산하여서 가장높은 값을 가지는 eps 거리를 최적의 값으로 본다.
for eps in np.arange(0.2, 1, 0.1): print(f"eps: {eps:.2f}",end=' // ') dbscan = DBSCAN(eps=eps, min_samples=2) dbscan.fit(df) if max(set(dbscan.labels_))==-1: # 모두 Noise로 배정받을 경우 print("모두 Noise이므로 eps를 키워야함") elif max(set(dbscan.labels_))== 0 : # 한개의 군집만 존재하는 경우 print("군집이 오직 한개이므로 eps를 줄여야함") else: score = silhouette_score(df[dbscan.labels_!=-1], dbscan.labels_[dbscan.labels_!=-1]) print(f"silhouette idx : {score:.3f}\n")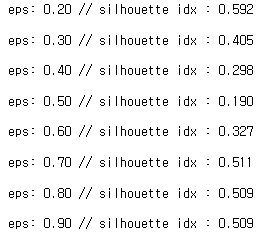 반응형
반응형'Data Science > ML&DL 모델' 카테고리의 다른 글
AutoEncoder 개념 및 종류 (0) 2022.10.31 Transformer Model 개념 및 모델 구조 (0) 2022.10.28 서포트 벡터 머신(SVM,Support Vector Machine) 파이썬 구현하기(cvxpy, sklearn (0) 2022.10.14 Hierarchy Clustering(계층적 군집화) 및 Dendrogram Visualization(덴드로그램 시각화) - AgglomerativeClustering, linkage, dendrogram (0) 2022.10.05 K-means Clustering 파이썬 구현하기 (0) 2022.10.05