-
Uncertainty Quantification(불확실성의 정량화)Data Science/데이터마이닝 2022. 11. 26. 11:28반응형
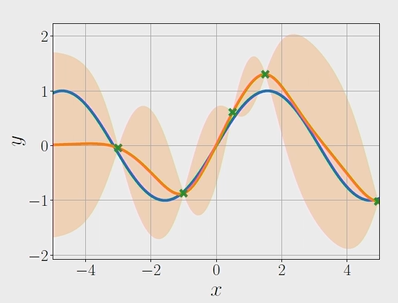
아래그림은 x축이 독립변수, y축이 종속변수이며 5개의 학습 데이터(초록색 x)가 주어진 상태이다.
파란색 line이 데이터를 생성하는 분포이며, 주황색 line이 생성된 regression 모델이다.
주황색으로 칠해진 배경은 불확실성(uncertainty)를 의미한다.
실제로 값이 관측된 구간에서는 불확실성이 0에 가깝지만,
관측값 사이의 거리가 멀고 값의 차이가 높을 수록 불확실성은 커지는 것을 확인할 수 있다.
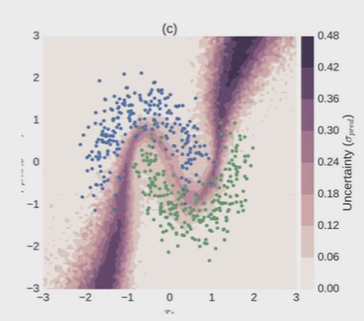
이진 분류 문제에서의 불확실성은 아래와 같이 표현될 수 있다.
이러한 불확실성은 데이터의 증가를 통해서 해결할 수 있기 때문에 epistemic uncertainty라고 한다.
그렇다면 반대로 데이터 자체에서 불확실성을 가지고 있는 Aleatoric uncertainty도 존재한다.
대표적으로 이미지 데이터에서의 segmentation을 예로 들수 있다.
아래의 그림에서와 같이 객체들의 경계가 명확하지 않거나 겹치는 부분에는 두개 이상의 class가 존재하면서 데이터 자체에서의 불확실성을 품고 있다.

수치형 데이터에서도 동일한 독립변수가 각기 다른 종속변수를 가진다면 이또한 aleatoric uncertainty라고 할수 있다.
(검수자가 그날의 컨디션에 따라서 같은 상태의 제품을 양품/불량품으로 판별하는 경우)
반응형'Data Science > 데이터마이닝' 카테고리의 다른 글
편상관계수 정의 및 파이썬 코드 구현(Partial Correlation Coefficient) (1) 2023.05.07 스마트팩토리에서 수치 데이터 기반 예측 모델 프로젝트를 하면서 주의할 점들 (0) 2023.04.23 머신러닝/딥러닝 하이퍼파라미터 최적화(ML/DL Hyperparameter Optimization) (0) 2022.11.26 Explainable AI & Interpretable ML (0) 2022.11.23 머신러닝에서의 이상 탐지 종류(Anormaly Detection) (0) 2022.11.21