-
[정규화,sklearn] MinMaxScaler, StandardScaler, RobustScalerData Science/Pandas & Numpy&Scikit-learn 2021. 9. 14. 15:47반응형
예측 모델을 위한 입력 피처를 구성하기 위해서는 수치형 값을 정규화 해야한다.
컬럼별로 수치형 값의 범위가 다를 경우 모델이 정확하게 학습되지 않을 수 있다.
본 포스팅에서는 각 컬럼들이 비슷한 범위를 가지게 하는 세가지 방법을 소개한다.
데이터 준비
import pandas as pd df=pd.DataFrame({ 'ID':[1,2,3,4,5], 'name':['아메리카노','바닐라라떼','아메리카노','민트초코','아메리카노'], 'tumbler':['N','Y','Y','N','N'], 'Age':[25,31,18,22,35], 'weight':[88.5,65.3,61.6,77.4,89.9] }) print(df)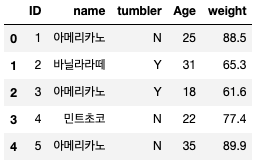
데이터 타입 확인
print(df.dtypes)
수치형 컬럼 지정
해당 데이터에서 ID컬럼은 int64 타입을 가지지만 의미상으로는 고유한 ID이기 때문에 정규화 대상에서 제외한다.
numerical_list = ['Age','weight']정규화 적용
-MinMaxScaler
from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler() df[numerical_list] = scaler.fit_transform(df[numerical_list]) print(df)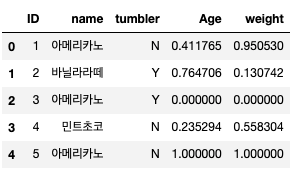
-StandardScaler
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() df[numerical_list] = scaler.fit_transform(df[numerical_list]) print(df)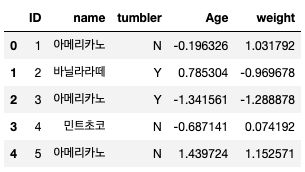
-RobustScaler
from sklearn.preprocessing import RobustScaler scaler = RobustScaler() df[numerical_list] = scaler.fit_transform(df[numerical_list]) print(df)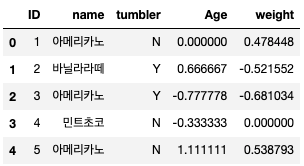
참고문헌
https://scikit-learn.org/stable/modules/classes.html#module-sklearn.preprocessing
https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.MinMaxScaler.html
https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.StandardScaler.html
https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.RobustScaler.html
반응형'Data Science > Pandas & Numpy&Scikit-learn' 카테고리의 다른 글
[Pandas] Pandas를 통한 데이터 전처리 (0) 2022.09.13 회귀모델에서 타겟(y)값의 정규화 방법 비교 실험 (0) 2022.05.27 [Python]다중 조건으로 데이터 프레임 특정 행 추출하기(데이터 프레임 필터링) (0) 2022.05.10 [인코딩,sklearn] Ordinal Encoding (0) 2021.09.14 [인코딩,sklearn] One-Hot Encoding (0) 2021.09.14