-
파이썬 데이터 병합(데이터프레임 핸들링, Join/Pandas.merge/Pandas.concat)카테고리 없음 2022. 9. 27. 15:22반응형
1. 데이터 병합(Join) 종류
- Inner join(교집합) : 두 데이터에서 기준값이 일치하는 데이터만 병합
- Outer join(합집합) : 두 데이터의 모든값 병합
- Left join(차집합 좌 - 우) : 좌측 데이터의 기준값과 일치하는 데이터만 병합
- right join(차집합 우 - 좌) : 우측 데이터의 기준값과 일치하는 데이터만 병합
2. Join
기존 데이터 프레임과 주어진 데이터프레임을 Index 기준으로 병합한다.
병합된 데이터 프레임은 결과로 반환된다.
기본 병합 키 : Index
기본 병합방식 : left join (left,right,inner,outer 변경 가능)
※ suffix 미지정시 두 데이터간에 중복되는 컬럼명을 가지면 안된다.
import pandas as pd df1 = pd.DataFrame({ 'a':[1,2,3], 'b':[10,11,12] }) df2 = pd.DataFrame({ 'c':[20,21,22], 'd':[30,31,32] }) # 데이터.join(추가데이터) re_df = df1.join(df2)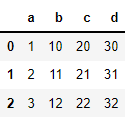
변경 가능한 파라미터는 아래와 같다.
파라미터 기능 기본값 사용가능값 how 병합 방식 설정 left left,right,inner,outer lsuffix 좌측 데이터 구분명 None 문자열(중복되는 컬럼 이름에 뒤에 붙음) rsuffix 우측 데이터 구분명 None 문자열(중복되는 컬럼 이름에 뒤에 붙음) import pandas as pd df1 = pd.DataFrame({ 'a':[1,2,4], 'b':[10,11,12], 'c':[44,45,46], }) df2 = pd.DataFrame({ 'a':[1,2,3,4], 'c':[20,21,22,23], 'd':[30,31,32,33] }) re_df = df1.join(df2, how='inner', lsuffix='_l',rsuffix='_r') re_df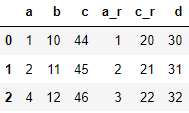
3. Pandas.merge
주어진 두 데이터프레임을 주어진 기준(파라미터 "on")으로 병합한다.
병합된 데이터 프레임은 결과로 반환된다.
기본 병합 키 : 없음, 필수로 지정해야함
기본 병합방식 : left join (left,right,inner,outer 변경 가능)
기본 병합방향 : 수직 (수평 변경 가능)
※ suffix 미지정시 자동적으로 left data에 x, right data에 y가 지정된다.
import pandas as pd df1 = pd.DataFrame({ 'a':[1,2,4], 'b':[10,11,12], 'c':[20,22,23], }) df2 = pd.DataFrame({ 'a':[1,2,3,4], 'b':[10,11,12,13], 'c':[20,21,22,23], 'd':[30,31,32,33] }) # pd.merge(데이터1,데이터2,on='병합기준') re_df = pd.merge(df1,df2,on='a') re_df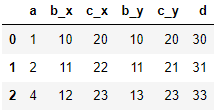
변경가능한 파라미터는 아래와 같다.
파라미터 기능 기본값 사용가능값 on 병합 기준 설정 없음 두 데이터에 모두 존재하는 중복 컬럼 how 병합 방식 설정 inner left,right,inner,outer suffixes 좌/우측 데이터 구분명 ('x','y') 두개 문자열을 가지는 튜플
(중복되는 컬럼 이름에 뒤에 붙음)re_df = pd.merge(df1,df2,on=['a','c'],suffixes=('_left','_right')) re_df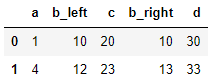
4. Pandas.concat
주어진 두 데이터프레임을 주어진 방향으로 병합한다.
이때 앞선 두 방법은 수평적 병합만을 지원하는 반면, concat은 수직/수평적 병합 모두를 지원한다.
병합된 데이터 프레임은 결과로 반환된다.
기본 병합 키 : 없음
기본 병합방식 : outer join (수평방향 변경 가능)
※ key(suffix) 미지정시 중복된 컬럼 또는 인덱스를 그대로 반영한다.
import pandas as pd df1 = pd.DataFrame({ 'a':[1,2,4], 'b':[10,11,12], 'c':[20,22,23], }) df2 = pd.DataFrame({ 'a':[1,2,3,4], 'b':[10,11,12,13], 'c':[20,21,22,23], 'd':[30,31,32,33] }) # pd.concat([데이터1,데이터2]) re_df = pd.concat([df1,df2]) re_df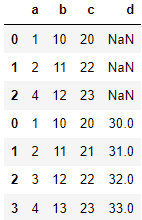
concat에서 사용 가능한 파라미터는 아래와 같다.
파라미터 기능 기본값 사용가능값 axis 병합 방향 설정 0(수직) 0(수직), 1(수평) join_axes 병합 기준 설정 없음 원하는 데이터의 인덱스 또는 컬럼 join 병합 방식 설정 outer left,right,inner,outer key 좌/우측 데이터 구분명 없음 두개 문자열을 가지는 리스트
(이중 인덱스 또는 컬럼으로 배정)ignore_index 병합 후 인덱스 재부여 False False, True 병합 후 인덱스 새로 배정하기
re_df = pd.concat([df1,df2],ignore_index=True) re_df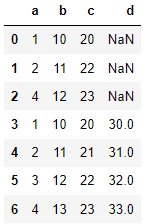
각 데이터에 따라서 이중 인덱스 배정하기
re_df = pd.concat([df1,df2],keys=['first','second']) re_df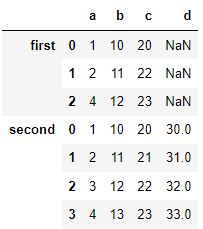
수평으로 병합하기 및 이중 컬럼 배정
re_df = pd.concat([df1,df2],axis=1,keys=['first','second']) re_df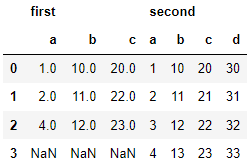 반응형
반응형